AWS Lambda Reserved Concurrency vs Retry
When you configure an AWS Lambda, you can configure it to only allow a certain number of concurrent executions through the “Reserve concurrency” setting. For example, it is possible to configure a Lambda to only allow a single concurrent execution.

Even though AWS provides lots of documentation on the topic, there was just too much of it (or I was just too lazy to read it all) and I was not able to fully understand what was the behavior when no more concurrent executions were available. I therefore went ahead and tried it out.
Creating a test lambda
First I created a test lambda that takes as input a JSON document that looks like this:
{
"name": "Some name",
"numberOfSecondsToWait": 5
}With this input, it will:
- Log the value of the
nameproperty. - Waits for
numberOfSecondsToWaitseconds.
Here’s the code of the lambda:
Invoking the lambda
In order to easily run the lambda, I created a little helper script to invoke it and log some relevant information. This was done using the AWS Tools For PowerShell library.
As you can see, the function accepts an InvocationType parameter. The possible values are RequestResponse (you want to wait for the response), Event (you want to fire the lambda and forget about it) and DryRun (not relevant for my purpose here). See the Invoke API for more details on this parameter.
With this in place, I configured my lambda with Concurrency=Use unreserved account concurrency. I then executed two lambdas at the same time with InvocationType=RequestResponse. Without much surprises, both were executed in parallel and completed at about the same time.

I then changed the configuration of my lambda to only allow 1 concurrent execution.
With this in place, my question was: if I try to run 2 lambdas in parallel with InvocationType=RequestResponse, will one of my call wait for the other to complete or will it fail? Here’s the answer.

So I just got my first finding:
With InvocationType=RequestResponse, if all the reserved executions are already busy, I will get a “rate exceeded” error. It will not wait. My invocation is lost. Gone. It won’t be retried by AWS. It would be my responsibility to implement some retry mechanism.
Now, what about InvocationType=Event? If I start 2 executions, will one of these wait until the other one is completed? Let’s try it out with some long duration (14.5 minutes).

By looking at the console output, we see that starting both lambdas completed really fast (it took 0 seconds). Also, the 202 Accepted status code tells us that the request was accepted by the Lambda service and that it will run eventually.
Let’s look in CloudWatch Logs to see what happened:

These logs give a few important insights:
- Both requests (
Long 1, andLong 2) were executed one after the other. - It took some time (about 5 minutes) for
Long 2to start onceLong 1was completed.
But why did it take so long for Long 2 to start? The Throttles lambda metric will help us to see exactly when the operation was retried. Here’s the definition of the metric:
The number of invocation requests that are throttled. When all function instances are processing requests and no concurrency is available to scale up, Lambda rejects additional requests with TooManyRequestsException. Throttled requests and other invocation errors don’t count as Invocations or Errors.
Let’s look at this metric in CloudWatch.

What we see in this graph is that my second invocation was retried a few times. At the beginning, a few retry happened very quickly. But after a few minutes, the operation was retried about only once per 5 minutes. This explains why there was such a long delay between the completion of Long 1 and the beginning of Long 2.
So here are my findings with InvocationType=Event:
When the lambda service accepts my request, it puts it in some sort of queue. When all the reserved executions are already busy, it will retry the execution later. I can be confident that my lambda will be invoked eventually. I don’t know when, but it will. I can go watch tv…
This behavior is confirmed by the AWS doc:
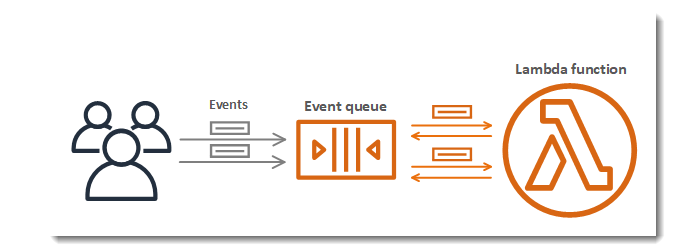
If the function doesn’t have enough concurrency available to process all events, additional requests are throttled. For throttling errors (429) and system errors (500-series), Lambda returns the event to the queue and attempts to run the function again for up to 6 hours. The retry interval increases exponentially from 1 second after the first attempt to a maximum of 5 minutes. However, it might be longer if the queue is backed up. Lambda also reduces the rate at which it reads events from the queue.
This is illustrated in this image.
Warning: retry of errors raised by your code
I here talked about errors caused by throttling. Beware that if your function returns an error when called asynchronously (i.e. your code was called but it failed), the retry behavior is not the same at all. You will not get a large number of automatic retries for up to 6 hours. The invocation is still added to a queue but it is only retried at most 3 times.
Lambda manages the function’s asynchronous event queue and attempts to retry on errors. If the function returns an error, Lambda attempts to run it two more times, with a one-minute wait between the first two attempts, and two minutes between the second and third attempts. Function errors include errors returned by the function’s code and errors returned by the function’s runtime, such as timeouts.
This number of attempts can be configured in the “Asynchronous invocation” section.
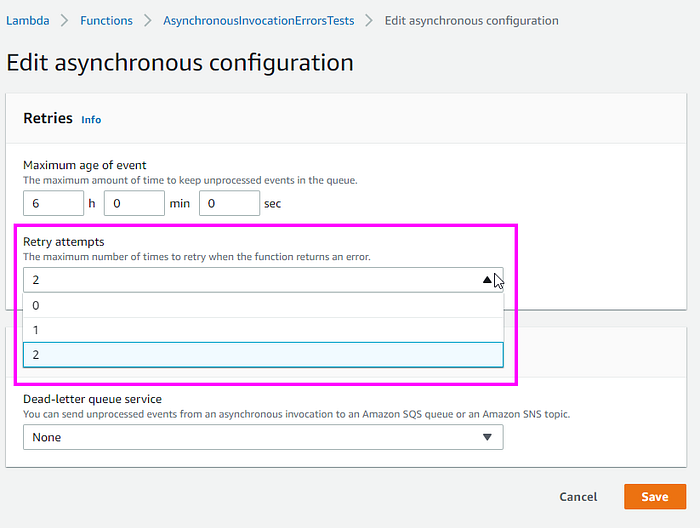
Note that only the values 1, 2 and 3 can be used. Therefore, if you want to be sure that your asynchronous invocations are not lost after 3 attempts, it is highly suggested to configure a dead letter queue.
Conclusion
When I use the Invoke API myself directly (i.e. not indirectly through another service like SNS) and all the concurrent executions are busy:
- With
InvocationType=RequestResponse, I will receive an error. I have to retry the operation myself. - With
InvocationType=Event, my request will succeed. It will be retried by AWS (for up to 6 hours).
Thanks to these findings, I now have an easy way to run some heavy processing without concurrent executions. For example, I sometimes have to insert large amounts of data in a database. Since this is a very CPU intensive operation, I don’t want to allow multiple concurrent executions of this code. To solve this, I can simply:
- create a lambda with
ReserveConcurrency=1 - put my heavy processing in that lambda
- start that lambda with
InvocationType=Eventwhenever the big operation is needed
With this, I can start the lambda multiple times in parallel and I am confident that my costly database operations will run one after the other without the need for something like SQS. There is already a queue included with Lambda.
Thanks Lambda!
